在学习和工作中,难免有一些需求,比如今天的主题就是:将pdf转换成word,其实网络上还有一些工具也能实现转化,往往这些工具有的需要收费,而破解的可能会携带病毒让我们用得不是很放心;其次这些工具有的只能一次转换一个,如果我们想批量转换,那么就得一个一个转,很是麻烦。
我们今天在这里使用python来实现对pdf文件进行批量转换为word。如果你想直接使用,那么直接看第1与第5条里面的代码即可。下面,就开始我们的操作。
1.如果你的python环境中没有安装pdf2docx模块,那么使用下面的命令进行安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pdf2docx
2.导入我们需要使用的模块,如下:
import PyPDF2
from pdf2docx import Converter
import os
3.接下来就是编写转换函数的部分,代码如下:
def pdf2doc(pdf_name, out_file):
# 转化pdf文件
# pdf_name:为pdf全路径名称 示例 D://***//**.pdf
# out_file:为输出全路径的word名称 示例 D://***//**.word
cv = Converter(pdf_name)
try:
# file_name 要转换成word的文件名 start: 开始页 end 结束页 默认是0开始到最后一页
cv.convert(str(out_file), start=0, end=None)
except Exception as e:
print("转化出错:", e)
return False
cv.close()
return True
4.批量函数:获得某个文件夹下所有的pdf文件,并将pdf文件改名为word,且打印出来:
def get_pdf_files(path,outPut_file):
# 遍历文件夹下所有文件,将其转成对应的pdf
# os.walk() 遍历文件夹
for root, dirs, files in os.walk(path):
for file in files:
# 使用 glob.glob() 获取所有符合条件的文件
if file.endswith('.pdf'):
pdf_file_path = os.path.join(root, file) # 获取完整文件路径
file = pdf_file_path.replace(".pdf",'.docx')
print(file) #打印改名的后的word文件名,只是用来看看,下面的函数能够使用上
#pdf2doc(pdf_name=pdf_file_path,out_file=file) #这里就开始了批量转化,我这里先注释掉
5.类似之前有个老师说的一句话,写程序有时候像玩积木,将两个积木搭起来,就能获得一个新的东西。我们在这里将两个函数组合起来,就能够进行批量处理了。完整的代码如下:
import PyPDF2
from pdf2docx import Converter
import os
def pdf2doc(pdf_name, out_file):
# 转化pdf文件
cv = Converter(pdf_name)
try:
# file_name 要转换成word的文件名 start: 开始页 end 结束页 默认是0开始到最后一页
cv.convert(str(out_file), start=0, end=None)
except Exception as e:
print("转化出错:", e)
return False
cv.close()
return True
def get_pdf_files(path,outPut_file):
# 遍历文件夹下所有文件,将其转成对应的pdf
# os.walk() 遍历文件夹
for root, dirs, files in os.walk(path):
for file in files:
# 使用 glob.glob() 获取所有符合条件的文件
if file.endswith('.pdf'):
pdf_file_path = os.path.join(root, file) # 获取完整文件路径
file = pdf_file_path.replace(".pdf",'.docx')
print(file)
pdf2doc(pdf_name=pdf_file_path,out_file=file)
get_pdf_files('pdf文件夹路径', '需要保持的word文件夹路径')
6.直接在一个新的py文件运行上面代码就可以了,下面是我某一篇运行的结果,左边为原始pdf文件,右边为转换后的word文件
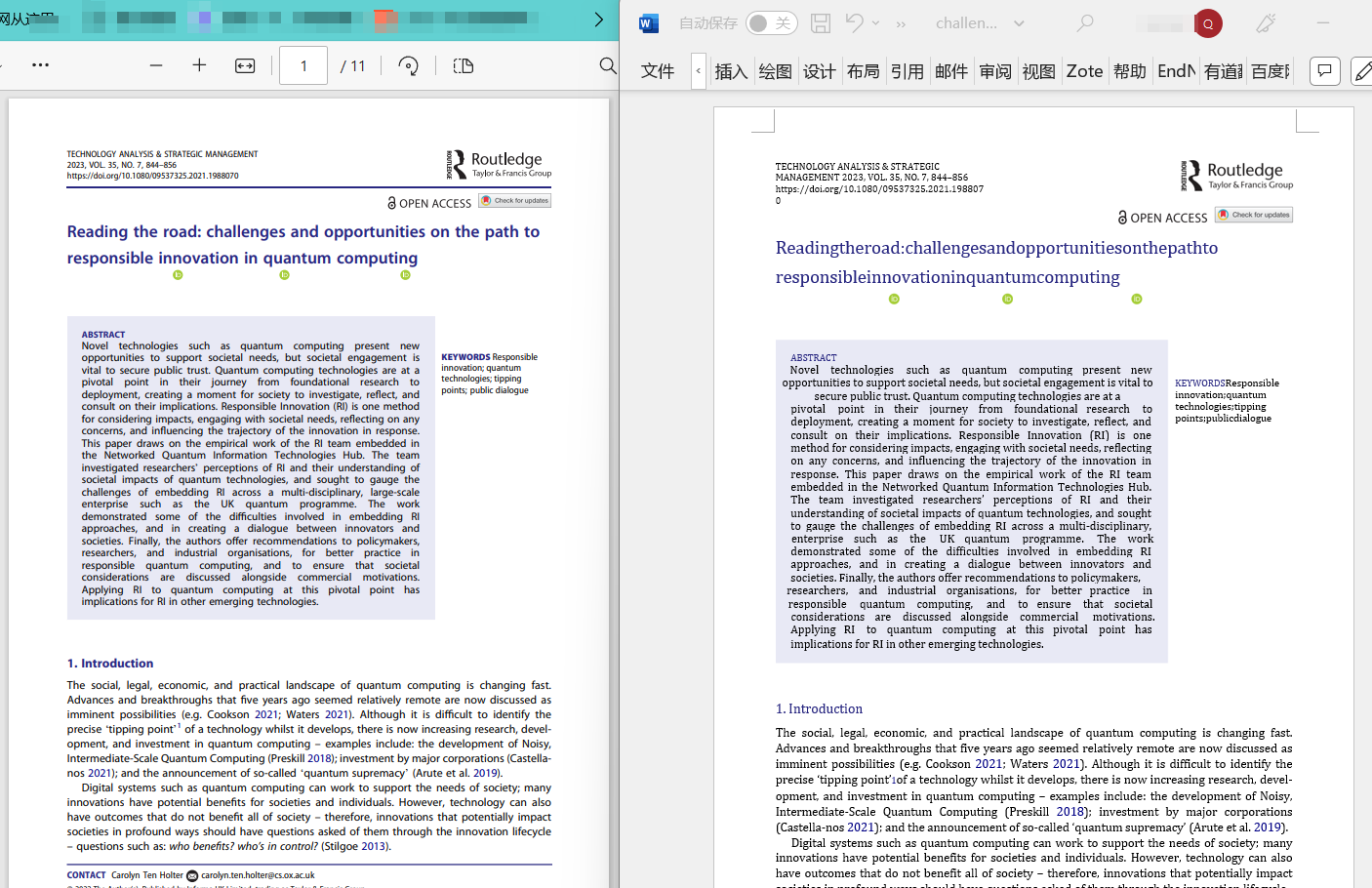
7.注意:有的转换后的word可能会出现问题,这个需要自己打开word与pdf对照下,并修改修改。
注意:欢迎转载,转载时请注明来源
